# Import csv libraryimportunicodecsv# Define function to read and store datadefread_csv(filename):withopen(filename,'rb')asf:reader=unicodecsv.DictReader(f)returnlist(reader)enrollments=read_csv('data/enrollments.csv')daily_engagement=read_csv('data/daily_engagement.csv')project_submissions=read_csv('data/project_submissions.csv')# Print out first element of each listprint('Enrollments:')print(enrollments[0])print('Daily engagement:')print(daily_engagement[0])print('Project submissions:')print(project_submissions[0])
# Import libraryfromdatetimeimportdatetimeasdt# Takes a date as a string, and returns a Python datetime object # If there is no date given, returns Nonedefparse_date(date):ifdate=='':returnNoneelse:returndt.strptime(date,'%Y-%m-%d')# Takes a string which is either an empty string or represents an integer# and returns an int or None.defparse_maybe_int(i):ifi=='':returnNoneelse:returnint(i)# Clean up the data types in the enrollments tableforenrollmentinenrollments:enrollment['cancel_date']=parse_date(enrollment['cancel_date'])enrollment['days_to_cancel']=parse_maybe_int(enrollment['days_to_cancel'])enrollment['is_canceled']=enrollment['is_canceled']=='True'enrollment['is_udacity']=enrollment['is_udacity']=='True'enrollment['join_date']=parse_date(enrollment['join_date'])print('Enrollments:')enrollments[0]
# Clean up the data types in the engagement tableforengagement_recordindaily_engagement:engagement_record['lessons_completed']=int(float(engagement_record['lessons_completed']))engagement_record['num_courses_visited']=int(float(engagement_record['num_courses_visited']))engagement_record['projects_completed']=int(float(engagement_record['projects_completed']))engagement_record['total_minutes_visited']=float(engagement_record['total_minutes_visited'])engagement_record['utc_date']=parse_date(engagement_record['utc_date'])print('Daily engagement:')daily_engagement[0]
# Clean up the data types in the submissions tableforsubmissioninproject_submissions:submission['completion_date']=parse_date(submission['completion_date'])submission['creation_date']=parse_date(submission['creation_date'])print('Project submissions:')project_submissions[0]
# Rename the "acct" column in the daily_engagement table to "account_key".forengagement_recordindaily_engagement:engagement_record['account_key']=engagement_record['acct']delengagement_record['acct']print('Daily engagement - account key:')daily_engagement[0]['account_key']
Daily engagement - account key:
'0'
# Define function to get unique studentsdefget_unique_students(data):unique_students=set()fordata_pointindata:unique_students.add(data_point['account_key'])returnunique_students
# Total number of rows and the number of unique students (account keys)# in each table.print('Total enrollment records:')print(len(enrollments))unique_enrolled_students=get_unique_students(enrollments)print('Total unique enrollment records:')print(len(unique_enrolled_students))print('Total daily engagement records:')print(len(daily_engagement))unique_engagement_students=set()unique_engagement_students=get_unique_students(daily_engagement)print('Total unique daily engagement records:')print(len(unique_engagement_students))print('Total project submission records:')print(len(project_submissions))unique_project_submitters=get_unique_students(project_submissions)print('Total unique project submission records:')print(len(unique_project_submitters))
Total enrollment records:
1640
Total unique enrollment records:
1302
Total daily engagement records:
136240
Total unique daily engagement records:
1237
Total project submission records:
3642
Total unique project submission records:
743
Problems in the Data
Missing Engagement Records
# Find one student enrollments where the student is missing from the daily engagement table# Output that enrollmentcounter=0forenrollmentinenrollments:student=enrollment['account_key']ifstudentnotinunique_engagement_students:print('Enrollment:')print(enrollment)break
# Find the number of surprising data points (enrollments missing from# the engagement table) that remain, if anycounter=0forenrollmentinenrollments:student=enrollment['account_key']ifstudentnotinunique_engagement_studentsandenrollment['days_to_cancel']!=0:counter+=1print('Enrollment:')print(enrollment)print('Counter:')print(counter)
# Create a set of the account keys for all Udacity test accountsudacity_test_accounts=set()forenrollmentinenrollments:ifenrollment['is_udacity']:udacity_test_accounts.add(enrollment['account_key'])print('Number of Udacity test accounts:')print(len(udacity_test_accounts))
Number of Udacity test accounts:
6
# Given some data with an account_key field, removes any records corresponding to Udacity test accountsdefremove_udacity_accounts(data):non_udacity_data=[]fordata_pointindata:ifdata_point['account_key']notinudacity_test_accounts:non_udacity_data.append(data_point)returnnon_udacity_data
# Remove Udacity test accounts from all three tablesnon_udacity_enrollments=remove_udacity_accounts(enrollments)non_udacity_engagement=remove_udacity_accounts(daily_engagement)non_udacity_submissions=remove_udacity_accounts(project_submissions)print('Non Udacity enrollments:')print(len(non_udacity_enrollments))print('Non Udacity engagements:')print(len(non_udacity_engagement))print('Non Udacity submissions:')print(len(non_udacity_submissions))
Non Udacity enrollments:
1622
Non Udacity engagements:
135656
Non Udacity submissions:
3634
Refining the Question
# Creates a dictionary named paid_students containing all students who either# haven't canceled yet or who remained enrolled for more than 7 days. The keys# are account keys, and the values are the date the student enrolledpaid_students={}forenrollmentinnon_udacity_enrollments:ifnotenrollment['is_canceled']orenrollment['days_to_cancel']>7:account_key=enrollment['account_key']enrollment_date=enrollment['join_date']paid_students[account_key]=enrollment_dateifaccount_keynotinpaid_studentsor \
enrollment_date>paid_students[account_key]:paid_students[account_key]=enrollment_dateprint('Paid students:')print(len(paid_students))
Paid students:
995
Getting Data from First Week
# Takes a student's join date and the date of a specific engagement record,# and returns True if that engagement record happened within one week# of the student joining.defwithin_one_week(join_date,engagement_date):time_delta=engagement_date-join_datereturntime_delta.days<7andtime_delta.days>=0
# Creates a list of rows from the engagement table including only rows where# the student is one of the paid students we just found, and the date is within# one week of the student's join datedefremove_free_trial_cancels(data):new_data=[]fordata_pointindata:ifdata_point['account_key']inpaid_students:new_data.append(data_point)returnnew_datapaid_enrollments=remove_free_trial_cancels(non_udacity_enrollments)paid_engagement=remove_free_trial_cancels(non_udacity_engagement)paid_submissions=remove_free_trial_cancels(non_udacity_submissions)print('Paid enrollments:')print(len(paid_enrollments))print('Paid engagements:')print(len(paid_engagement))print('Paid submissions:')print(len(paid_submissions))paid_engagement_in_first_week=[]forengagement_recordinpaid_engagement:account_key=engagement_record['account_key']join_date=paid_students[account_key]engagement_record_date=engagement_record['utc_date']ifwithin_one_week(join_date,engagement_record_date):paid_engagement_in_first_week.append(engagement_record)print('Paid engagements in first week:')print(len(paid_engagement_in_first_week))
Paid enrollments:
1293
Paid engagements:
134549
Paid submissions:
3618
Paid engagements in first week:
6920
Exploring Student Engagement
# Import libraryfromcollectionsimportdefaultdict# Creates a dictionary of engagement grouped by student# The keys are account keys, and the values are lists of engagement records.engagement_by_account=defaultdict(list)forengagement_recordinpaid_engagement_in_first_week:account_key=engagement_record['account_key']engagement_by_account[account_key].append(engagement_record)
# Creates a dictionary with the total minutes each student spent in the classroom during the first week# The keys are account keys, and the values are numbers (total minutes)total_minutes_by_account={}foraccount_key,engagement_for_studentinengagement_by_account.items():total_minutes=0forengagement_recordinengagement_for_student:total_minutes+=engagement_record['total_minutes_visited']total_minutes_by_account[account_key]=total_minutes
#Import libraryimportnumpyasnp# Summarize the data about minutes spent in the classroomtotal_minutes=np.array(list(total_minutes_by_account.values()))print('Mean:',np.mean(total_minutes))print('Standard deviation:',np.std(total_minutes))print('Minimum:',np.min(total_minutes))print('Maximum:',np.max(total_minutes))
# Goes through a similar process as before to see if there is a problem# Locates at least one surprising piece of data and outputs itstudent_with_max_minutes=Nonemax_minutes=0forstudent,total_minutesintotal_minutes_by_account.items():iftotal_minutes>max_minutes:max_minutes=total_minutesstudent_with_max_minutes=studentprint('Max minutes:')print(max_minutes)forengagement_recordinpaid_engagement_in_first_week:ifengagement_record['account_key']==student_with_max_minutes:print('Engagement record:')print(engagement_record)
# Adapts the code above to find the mean, standard deviation, minimum, and maximum for# the number of lessons completed by each student during the first week# Load libraryfromcollectionsimportdefaultdictdefgroup_data(data,key_name):grouped_data=defaultdict(list)fordata_pointindata:key=data_point[key_name]grouped_data[key].append(data_point)returngrouped_dataengagement_by_account=group_data(paid_engagement_in_first_week,'account_key')defsum_grouped_items(grouped_data,field_name):summed_data={}forkey,data_pointsingrouped_data.items():total=0fordata_pointindata_points:total+=data_point[field_name]summed_data[key]=totalreturnsummed_datatotal_minutes_by_account=sum_grouped_items(engagement_by_account,'total_minutes_visited')defdescribe_data(data):print('Mean:',np.mean(data))print('Standard deviation:',np.std(data))print('Minimum:',np.min(data))print('Maximum:',np.max(data))print('Total minutes by account:')describe_data(np.array(list(total_minutes_by_account.values())))lessons_completed_by_account=sum_grouped_items(engagement_by_account,'lessons_completed')print('Lessons completed by account:')describe_data(np.array(list(lessons_completed_by_account.values())))
Total minutes by account:
Mean: 305.414718908
Standard deviation: 405.91261032
Minimum: 0.0
Maximum: 3564.7332645
Lessons completed by account:
Mean: 1.63216080402
Standard deviation: 3.00140182563
Minimum: 0
Maximum: 36
Number of Visits in First Week
# Finds the mean, standard deviation, minimum, and maximum for the number of# days each student visits the classroom during the first weekengagement_by_account=group_data(paid_engagement_in_first_week,'account_key')foraccount_key,engagement_for_studentinengagement_by_account.items():fordata_pointsinengagement_for_student:ifdata_points['num_courses_visited']>0:data_points['has_visited']=1else:data_points['has_visited']=0has_visited_by_account=sum_grouped_items(engagement_by_account,'has_visited')print('Students that visited in first week:')describe_data(np.array(list(has_visited_by_account.values())))
Students that visited in first week:
Mean: 2.91256281407
Standard deviation: 2.22037005491
Minimum: 0
Maximum: 7
Splitting out Passing Students
# Creates two lists of engagement data for paid students in the first week# The first list contains data for students who eventually pass the# subway project, and the second list contains data for students# who do notsubway_project_lesson_keys=['746169184','3176718735']pass_subway_project=set()passing_engagement=[]non_passing_engagement=[]forsubmissioninpaid_submissions:project=submission['lesson_key']rating=submission['assigned_rating']if((projectinsubway_project_lesson_keys)and(rating=='PASSED'orrating=='DISTINCTION')):pass_subway_project.add(submission['account_key'])forengagement_recordinpaid_engagement_in_first_week:ifengagement_record['account_key']inpass_subway_project:passing_engagement.append(engagement_record)else:non_passing_engagement.append(engagement_record)print('Passing engagement:')print(len(passing_engagement))print('Non passing engagement')print(len(non_passing_engagement))
Passing engagement:
4528
Non passing engagement
2392
Comparing the Two Student Groups
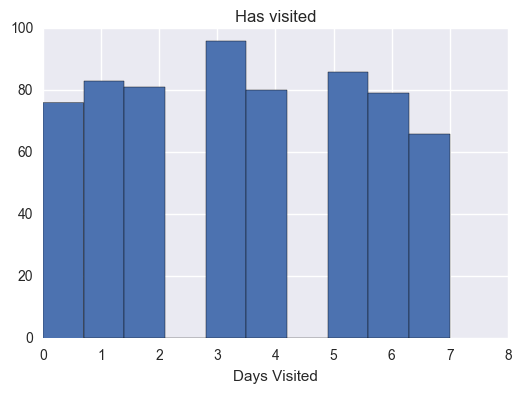
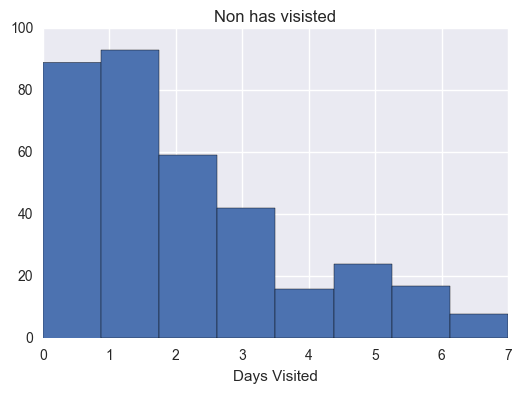
# Computes some metrics that are interesting and see how they differ for# students who pass the subway project vs. students who don'tpassing_engagement_by_account=group_data(passing_engagement,'account_key')has_visited_by_account=sum_grouped_items(passing_engagement_by_account,'has_visited')print('Has visited by account:')describe_data(np.array(list(has_visited_by_account.values())))non_passing_engagement_by_account=group_data(non_passing_engagement,'account_key')non_has_visited_by_account=sum_grouped_items(non_passing_engagement_by_account,'has_visited')print('Has not visited by account:')describe_data(np.array(list(non_has_visited_by_account.values())))
Has visited by account:
Mean: 3.42967542504
Standard deviation: 2.21298340866
Minimum: 0
Maximum: 7
Has not visited by account:
Mean: 1.95114942529
Standard deviation: 1.88929952676
Minimum: 0
Maximum: 7
Making Histograms
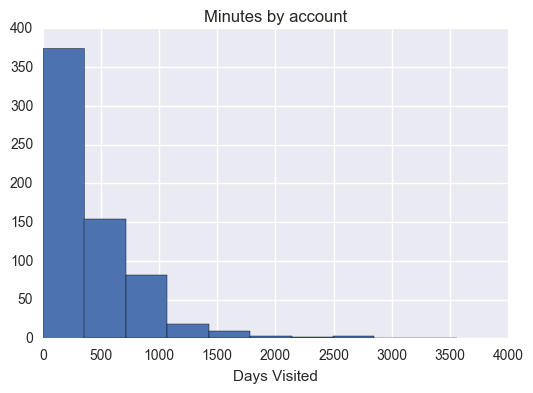
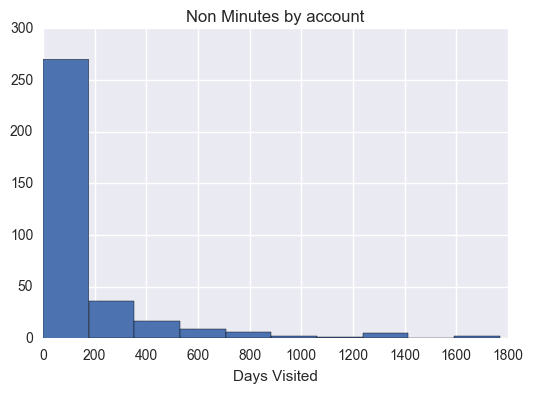
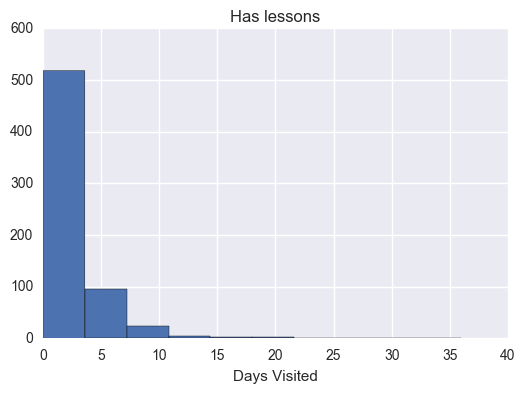
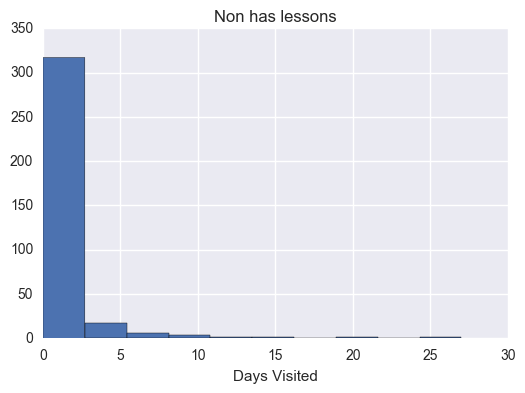
# Makes histograms of the three metrics we looked at earlier for both# students who passed the subway project and students who didn't# Ensure plot is displayed in notebook%pylabinline# Load librariesimportmatplotlib.pyplotaspltimportseabornassnshas_minutes_by_account=sum_grouped_items(passing_engagement_by_account,'total_minutes_visited')non_has_minutes_by_account=sum_grouped_items(non_passing_engagement_by_account,'total_minutes_visited')has_lessons_by_account=sum_grouped_items(passing_engagement_by_account,'lessons_completed')non_has_lessons_by_account=sum_grouped_items(non_passing_engagement_by_account,'lessons_completed')has_visited_by_account=sum_grouped_items(passing_engagement_by_account,'has_visited')non_has_visited_by_account=sum_grouped_items(non_passing_engagement_by_account,'has_visited')has_mins=[]foraccount_key,recordsinhas_minutes_by_account.items():has_mins.append(records)plt.figure(1)plt.hist(has_mins)plt.title("Minutes by account")plt.xlabel("Days Visited")non_has_mins=[]foraccount_key,recordsinnon_has_minutes_by_account.items():non_has_mins.append(records)plt.figure(2)plt.hist(non_has_mins)plt.title("Non Minutes by account")plt.xlabel("Days Visited")has_lessons=[]foraccount_key,recordsinhas_lessons_by_account.items():has_lessons.append(records)plt.figure(3)plt.hist(has_lessons)plt.title('Has lessons')plt.xlabel("Days Visited")non_has_lessons=[]foraccount_key,recordsinnon_has_lessons_by_account.items():non_has_lessons.append(records)plt.figure(4)plt.hist(non_has_lessons)plt.title('Non has lessons')plt.xlabel("Days Visited")has_visited=[]foraccount_key,recordsinhas_visited_by_account.items():has_visited.append(records)plt.figure(5)plt.hist(has_visited)plt.title('Has visited')plt.xlabel("Days Visited")non_has_visited=[]foraccount_key,recordsinnon_has_visited_by_account.items():non_has_visited.append(records)plt.figure(6)plt.hist(non_has_visited,bins=8)plt.title('Non has visisted')plt.xlabel("Days Visited")
Populating the interactive namespace from numpy and matplotlib
<matplotlib.text.Text at 0x10e3f6080>